生物标志物的重要性早已被公众、科学界和工业领域所认识。生物标志物可应用于疾病的分型、预测、治疗和预后,是临床应用转化前期基础,同时也是早期筛查的重要指标。
但真正被食品药品监督管理局批准的蛋白质生物标志物数量不多,目前临床上常规使用的蛋白质生物标志物更少,主要原因是生物标志物开发效率低,包括临床样本质量差、疾病的主观临床定义和客观蛋白质检测结果之间的差距,以及在发现阶段所识别的差异蛋白的高错误发现率。
在发现阶段关注到的绝大多数蛋白都不能成为有效的biomarker,只有少数的阳性候选蛋白具有真正的应用价值。因而开发一种从海量数据中筛选高通量、高灵敏、高准确性且成本合理的潜在生物标志物变得至关重要。
好消息是BIOTREE开发一种集成机器学习算法,将通量蛋白组的检测数据整合统计学检验和线性回归等特征选择算法,高效的鉴定和识别验证率高且分类效果显著的生物标志物诊断panel,从而达到极.佳的预判效果,为疾病的分型、预测以及治疗提供一个强有力的工具。
那么这个集成的机器学习算法的框架结构是怎样的呢?下面就由小编给大家娓娓道来:
框架结构
整套机器学习算法体系分为5个阶段:数据预处理、初筛选、潜在标志物组合、机器学习算法二次筛选、标志物验证与评价,如下图所示: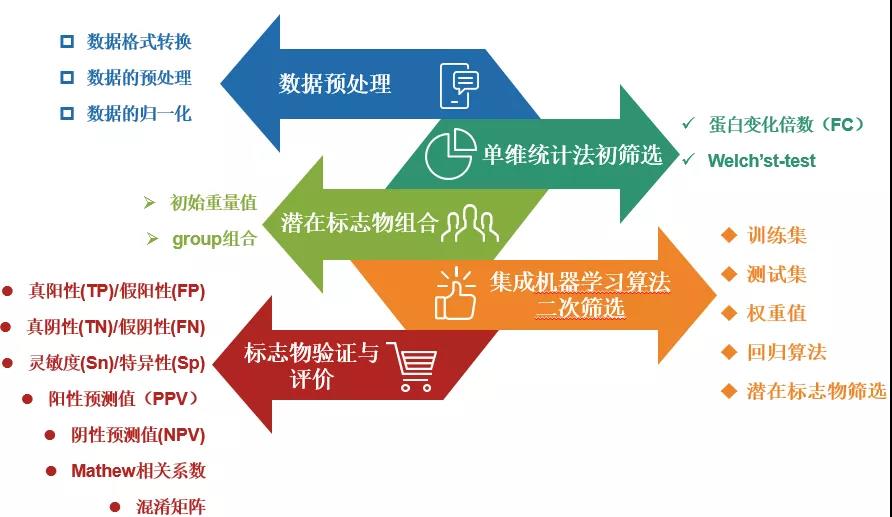
图1.集成机器学习算法框架结构
那么每一个阶段可以获得哪些核心的数据呢?
1.数据预处理与单维统计法初筛选
对高通量蛋白组的搜库定量数据进行格式转化、数据归一化等处理,筛选满足一定蛋白倍数变化(FC), 且双尾非配对Welch T检验小于0.01的差异蛋白。
2.潜在标志物组合
从差异蛋白中随机选择不超过一定数量的蛋白组成潜在的标志物组合(CPM),每个蛋白的初始重量值设为1,并设置至少1000种group,作为备选CPM。
3.机器学习算法二次筛选
对于每个候选CPM,按照一定比率随机生成一个训练集和一个测试集数据。利用集成的机器学习算法(多种特征选择算法)对group进行分析并惩罚迭代优化几种蛋白质的权重值。权重值越大说明该蛋白在区分不同分组样本中的作用贡献度越大。
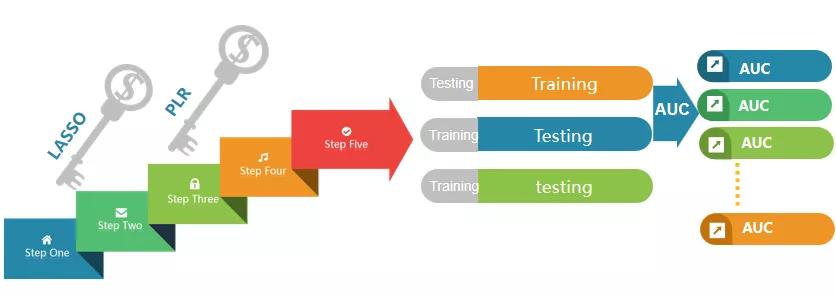
图2.机器学习算法二次筛选
4.标志物验证与评价
进行5倍交叉验证,根据Sn和1-Sp评分绘制ROC,计算AUC值。确定所有候选CPM的AUC值,并根据最高AUC值确定最优的标志物诊断panel,混淆矩阵分析来评估机器学习策略的可靠性。
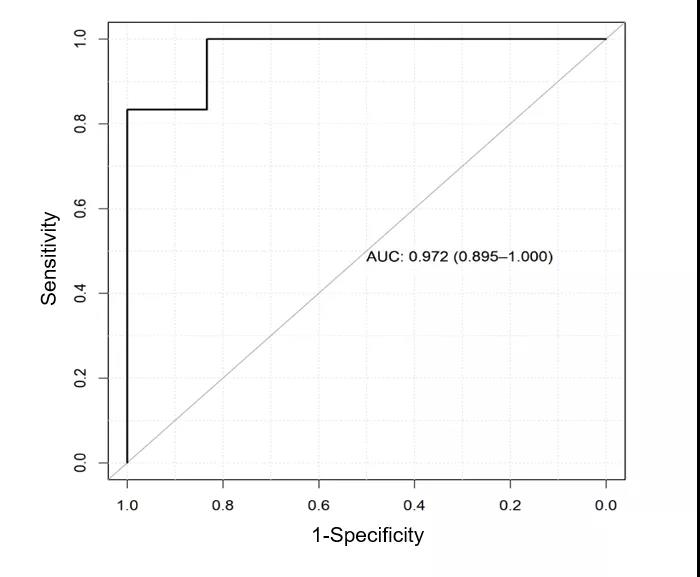
图3.标志物诊断panel的ROC曲线图
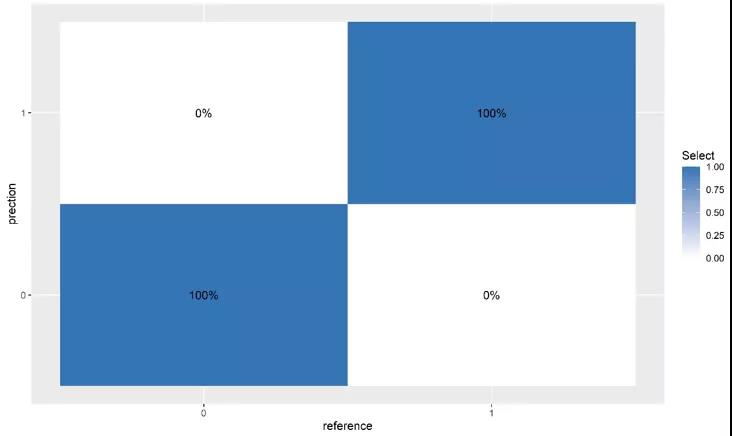
图4. 标志物诊断panel的混淆矩阵
基于以上的层层筛选,关关把控,三高一好(高准确度、高特异性、高阳性率,稳健性好)的临床队列样本标志物诊断panel就闪亮登场啦~
最特别的一点是,小样本量也能筛选出分类效果好,准确度高的标志物,不仅仅局限于临床队列大样本,让在医学领域辛勤耕耘的老师们都有机会在标志物研究领域做些研究啦~
蛋白标志物诊断panel研究应用案例
Ⅰ.口腔癌预后标志物研究
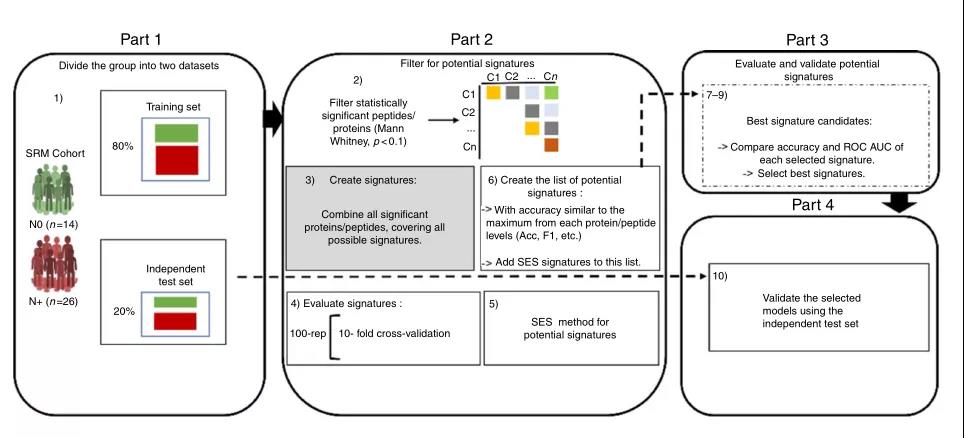
IF:12.121 PMID:30185791 Nat Commun 2018 09 05;9(1)
Oral squamous cell carcinoma-口腔鳞状细胞癌(OSCC)是头颈部最常见的恶性肿瘤,其不同区域具有特殊的组织病理学和分子特征因而限制了标准的肿瘤淋巴结转移预后分类。因此,作者将无淋巴结转移组(NO,n=14)与由淋巴结转移组(N+,n=26)的唾液样本进行蛋白组检测,并开发一种用于测量肽和蛋白质的预测能力的机器学习的工作流程,应用机器学习策略,评估了多肽和蛋白质的预测能力,筛选区分淋巴结转移OSCC患者(N+)和无淋巴结转移OSCC患者的预后标志物。
Ⅱ. 新冠肺炎的生物标志物
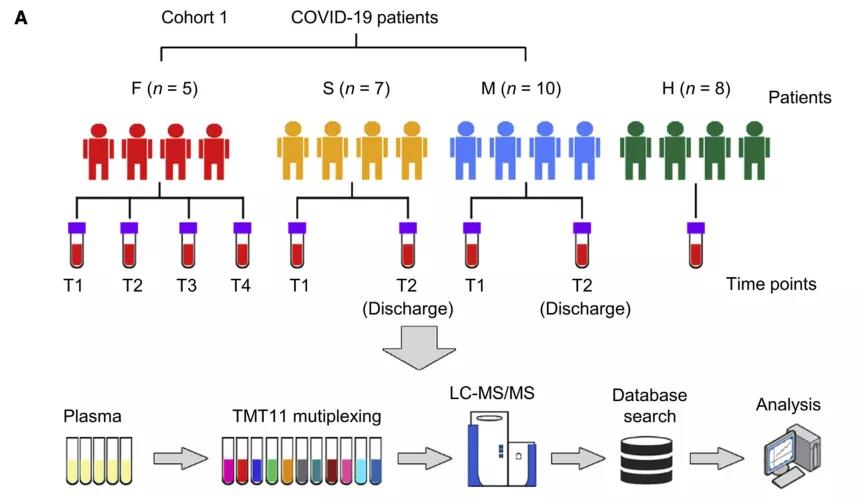
IF:22.553 Immunity 2020 11 17;53(5)
2019年冠状病毒病(COVID-19)的爆发是一场全球公共卫生危机。然而,对于新冠病毒-19的发病机制和生物标志物知之甚少,因此作者收集了来自武汉金银潭医院的新冠患者的血液样本进行TMT标记定量蛋白组检测并开发了一种机器学习的算法,确定一组可以准确区分/预测新冠肺炎不同症型的生物标记物组合。并且这些宿主蛋白的变化为COVID-19的发病机制提供了非常有价值的见解。